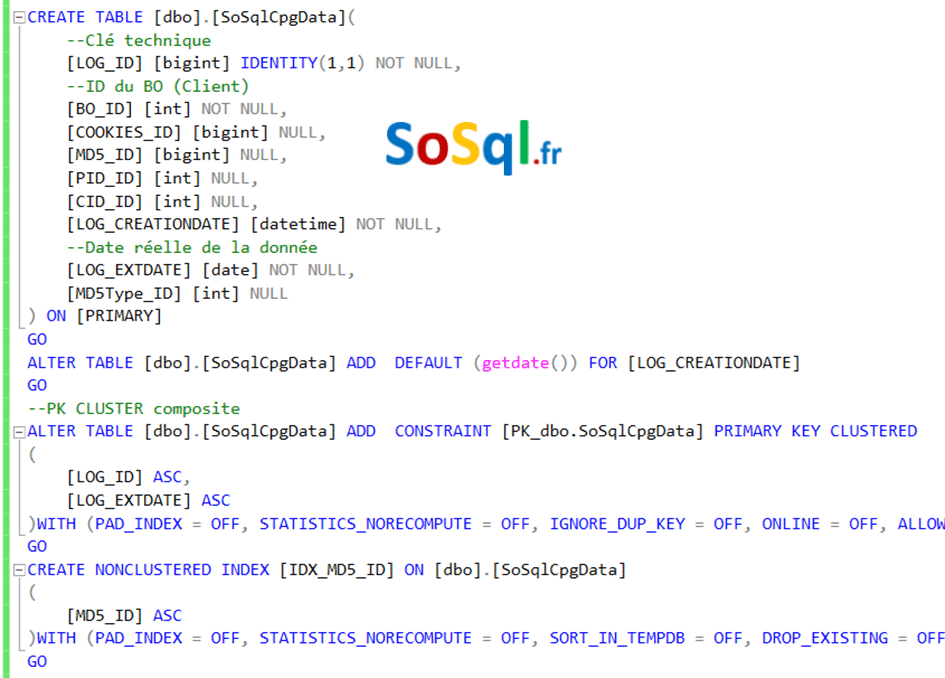

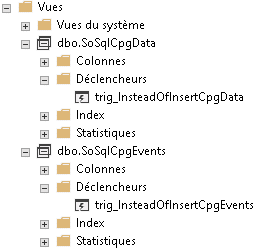
Le script pour générer les tables par clients avant d’avoir renommées les vues.

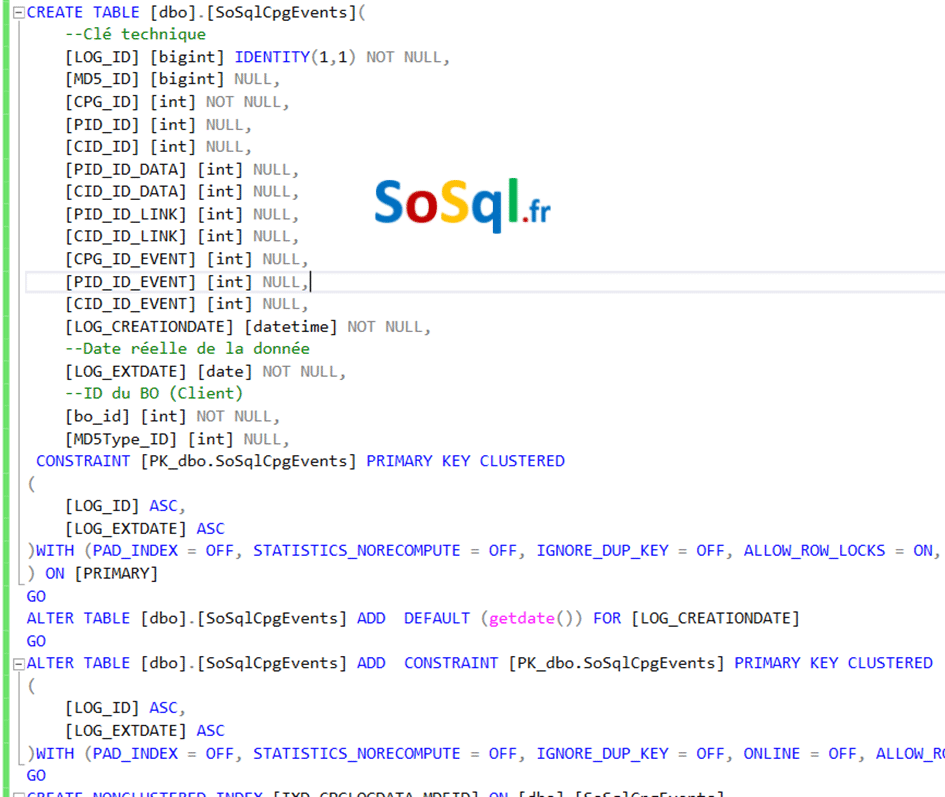
Le script pour générer les tables par clients après le renommage des vues (ajout d’un client).

Le script pour générer les tables par clients avant d’avoir renommées les vues.
Le script pour générer les tables par clients après le renommage des vues (ajout d’un client).